Weight-Tying: The Small, Gentle Read–Write Symmetry in Language Models
TL;DR — A language model at every step asks one simple question — given the numerical representation of the context so far, what is the probability of each vocabulary token being next? This writing unfolds that question cleanly: symbols first, forward & backward passes next, then the split of gradients that makes a single embedding table both reader and writer.
Flow (how to read this note)
- State the single desideratum that drives everything.
- Fix notation and the primitive objects we will manipulate.
- Walk forward: from tokens to probabilities.
- Walk backward: show the two distinct gradient paths into the embedding matrix and why they differ in character.
- Give a per-position worked derivative so nothing like magic.
- Read the consequences: symmetry, sparsity vs. density, and computational cost.
Prelude — the single desideratum
At each time step the model must compute a distribution over vocabulary tokens. Put plainly:
Given the numeric representation of the context so far, compute for every .
Everything that follows is a careful unpacking of how we represent the context, how the model turns that representation into logits and probabilities, and how gradients flow back into the same parameters that produced the representation.
Notation and primitives
We define the notation so the shapes and roles are obvious.
- — batch size (parallel independent sequences).
- — sequence length (tokens per sequence).
- — model hidden / embedding dimension.
- — vocabulary size.
Primitive tensors:
- : token indices after tokenization.
- : token embedding matrix; row is the vector for token .
- : positional embeddings (or any positional encoding of length ).
- : token vectors with position; for a sequence position ,
- : the transformer stack — a deterministic, differentiable function mapping .
- : final hidden states.
- Tied LM head: . (Tying enforces the same space for read/write.)
- : optional bias on logits.
- : scalar loss (we use mean cross-entropy over batch and time).
These primitives suffice to write the forward and backward equations compactly and exactly.
Forward pass

-
Embed + add position
Why: we need a dense vector representation for each token and a way to indicate position.
-
Transform
Why: the transformer composes attention and MLP layers to convert per-position inputs into context-aware representations.
-
Logits via tied head
Here indicates broadcasting the bias to every slice.
Why: each hidden scores every vocabulary row by inner product with that row; tying uses the same rows that produced embeddings.
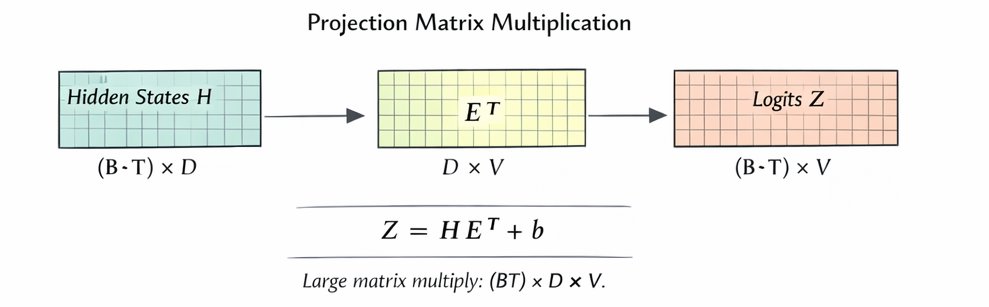
-
Softmax → probabilities
-
Mean cross-entropy loss For targets ,
These are the only forward equations required; they arise directly from the desideratum and the chosen primitives.
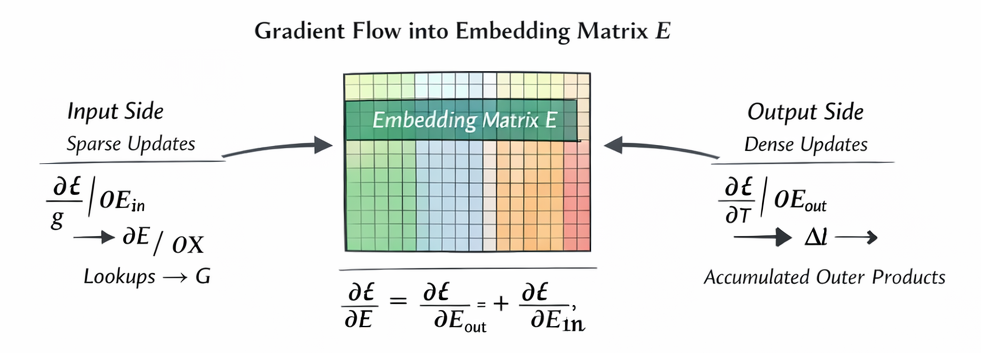
Backward pass — the two distinct contributions into (chain rule)
Because appears in two roles — as a lookup for inputs and as the transpose used to compute logits — the gradient decomposes into two additive pieces.
1. Immediate quantity from softmax + CE (logit residuals)
Define the logit residual tensor
This is the primitive starting point for gradients flowing into both the head (output side) and back into .
2. Output-side (projection) contribution — dense outer products
From we obtain the gradient on coming from the head:
Concretely, for vocabulary row ,
Character: dense — typically every receives some (small) contribution because the softmax probabilities are dense.
3. Input-side (lookup) contribution — sparse accumulation
Backpropagating through the transformer yields gradients to its inputs:
Since , the corresponding row of for the token receives:
Character: sparse — only embedding rows for tokens present in the mini-batch are touched.
4. Total gradient on
By linearity,
Pragmatically, frameworks accumulate both contributions into E.grad during a single backward pass.
A per-position worked derivative (so there is no mystery)
Fix a single position . Let , , and the correct index.
- .
- .
- Output-side update for from this position:
- Gradient into from the head:
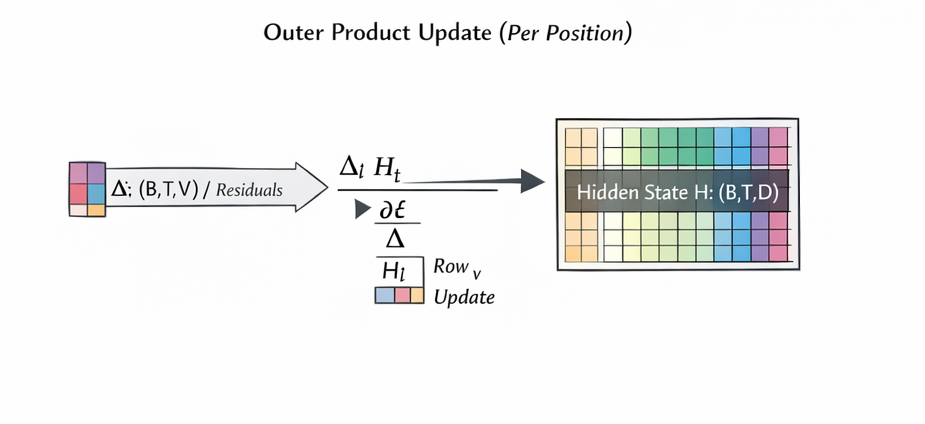
Summing these per-position contributions across recovers the tensor equations above. This shows how softmax residuals produce outer-product updates on and how they also feed back into the model via .
Computational Accounting
Consider , , , .
- .
- .
- Multiply by : .
So roughly multiply–accumulate operations are required for that single forward (or backward) pass through the head for the batch — a salutary reminder that the projection to vocabulary is often the dominant cost when is large.
Interpretation and Consequences
- Read–write symmetry. Tying means the vector space used to read tokens (embedding lookup) is identical to the space used to write tokens (projection). This reduces parameter redundancy and aligns representation and generation semantics.
- Two distinct learning channels. An embedding row changes for two reasons: (i) its use as an input (sparse updates) and (ii) its role in predicting outputs (dense outer-product updates). Both matter, but they have very different computational and statistical character.
- Sparsity vs. density. Input-side updates touch only the rows present in the batch (sparse). Output-side updates touch all rows (dense) because softmax spreads probability mass over the vocabulary. This explains why the head can be a bottleneck in large-vocabulary models.
- Practical design choices. If is large, we can look towards techniques like: adaptive softmax, vocabulary culling, sampling-based losses, or token clustering, to reduce the dense cost while preserving predictive fidelity.
Closing Remark
The model reads by looking up embedding rows and writes by taking inner products with those same rows; tying them makes the read and write vocabularies identical, and backpropagation simply sums the sparse read-derived corrections with the dense write-derived outer-product corrections into one embedding table.